Epochs enable snap developers to control how users receive a new application release when an application’s data format becomes incompatible with older versions of the application.
Epochs require snap version 2.38+.
Defining an epoch
Applications and their data formats are constantly evolving, and this requires applications to periodically break data compatibility with older versions. When this happens, applications and users often need to carefully manage data migration from one version to another, and this is where epochs can help.
By default, snaps have an epoch of ‘0’. When a new version breaks data compatibility with this old version, incrementing the epoch in the new release stops those old users automatically refreshing to the new version. To do this, add the following to your snap’s snapcraft.yaml:
epoch: 1
The revisions with the new epoch are invisible to users on the original epoch: 0; conversely, the old epoch is invisible to new users who always get the latest epoch with a fresh installation. You can still push updates to users of the old epoch by specifying epoch: 0 (or omitting the epoch) in its snapcraft.yaml, while pushing updates to the new version using epoch: 1. It’s a little like having subchannels.
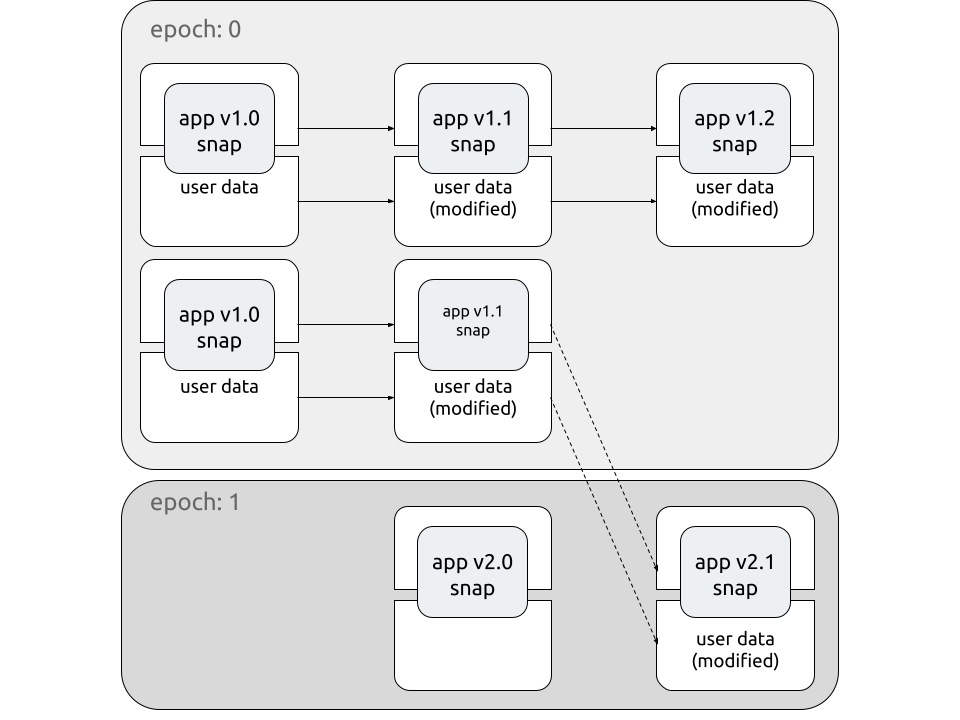
Migrating to a new epoch
Epochs alone track the format used but do not automatically migrate user data between application versions. This data is still copied, as it normally would, but snapd isn’t aware of its format, or how to migrate the data from an old epoch to a new one; the snap developer needs to manage and implement this process (e.g. run database migrations, etc.).
ⓘ snapd does not track which users have accessed a snap, or whether a user’s home directory is still accessible, or even if a user’s home directory is located in
/home/<user>. Similarly, epochs cannot automatically safeguard migrating version-dependent data in$SNAP_COMMONbecause, if a refresh fails, there’s no guaranteed way to retrieve the old data;snap revertwill not bring the data back
Your own data migration strategy could use hooks within your snapcraft.yaml, or rely on functionality within your application at run-time.
When you have confidence in a migration process, you can then label the new epoch with an asterisk (*) to indicate its compatibility with old data versions.
For example, to create a snap that says it knows how to read both epoch 0 data and epoch 1 data, but only write epoch 1 data, you add the following to your snapcraft.yaml:
epoch: 1*
The resulting snap acts as a bridge between epoch 0 and epoch 1. Users of the old version migrate automatically when they refresh. They will then upgrade to any newer releases in epoch 1, just like any new user. You can use revert to switch back to releases from a previous epoch, discarding any data changes done by the latest revision.
If users need to test data compatibility with the new epoch version, and the snap is not a confinement: classic snap, you can install both epoch 0 and epoch 1 snaps at the same time using Parallel installs. This allows your users to migrate only when they have the confidence to do so.
A big advantage with automatic migration is that the data transformation process needs to be supported only for a limited number of revisions. If a user neglects to update their system across epochs, for example, when they eventually refresh, they will be stepped through each epoch: 0 to 1*, 1 to 2*, and 2 onwards, for instance, by performing the migration process for each step as necessary. You don’t need to push old migration code to new versions of your application.
Epoch transitions
The following table illustrates which revision (R) and epoch (E) a user will receive when refreshing an application from stable and candidate channels:
| stable releases |
candidate releases |
stable for user 1 |
candidate for user 2 |
candidate for user 3 |
|
| 1 | R1E0 | - | R1E0 | R1E0 | - |
| 2 | R2E0 | - | R2E0 | R2E0 | - |
| 3 | - | R3E1 | R2E0 | R2E0 (!) | R3E1 |
| 4 | R4E0 | - | R4E0 | R4E0 (!) | R3E1 |
| 5 | R5E1 | - | R4E0 | R4E0 | R3E1 (!) |
| 6 | - | R6E1* | R4E0 | R6E1 | R6E1 |
| 7 | R6E1* | - | R6E1 | R6E1 | R6E1 |
| 8 | - | R7E1 | R6E1 | R7E1 | R7E1 |
Internal read/write configuration
Internally, snapd maintains a list of which revisions of a snap can read and write to each epoch. You can set these from snapcraft using passthrough. For example, 1* is equivalent to:
passthrough:
epoch:
read: [ 0, 1 ]
write: [ 1 ]
There are rules about what can be in read and write, but in general, you should not need to use this syntax at all. We’re mentioning it here because the store only supports the extended format, so you’ll see it if you query the store directly.
 Thanks!
Thanks!